Flow Matching: A Minimal Guide
Learning vector fields in continuous and discrete spaces
Flow Matching (FM) (Lipman et al., 2023) has seen impressive success in image and video generation [Link]. The key idea is to train a neural network to learn the underlying vector (velocity) field that deterministically pushes particles along this transport path.
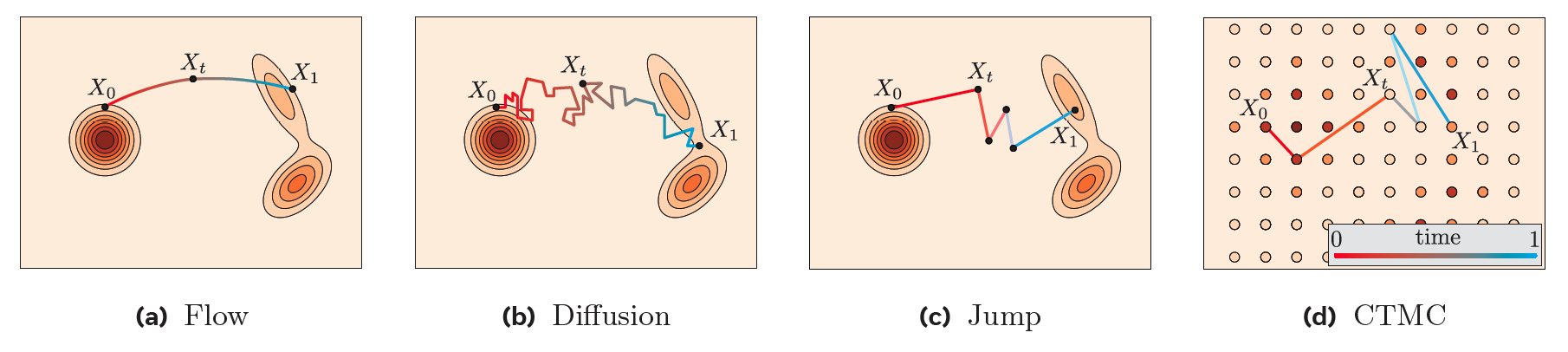
Continuous State Space
Problem setup
Consider a vector field \(\mathrm{v_t : \mathbb{R}^d \to \mathbb{R}^d}\) and define its flow map \(\mathrm{\phi_t}\) as the solution of the ODE
\[\begin{equation} \mathrm{\frac{d}{dt}\phi_t(x) = v_t(\phi_t(x)), \quad \phi_0(x) = x}.\notag \end{equation}\]Let \(\mathrm{p_0}\) and \(\mathrm{p_1}\) be the prior and data distributions, respectively. The marginal probability \(\mathrm{p_t:=[\phi_t]_\# p_0}\) is defined as the pushforward of \(\mathrm{p_0}\) under \(\mathrm{\phi_t}\). Equivalently, by change-of-variables [Link]:
\[\begin{equation} \mathrm{p_t(x) = p_0(\phi_t^{-1}(x)) \mid \det \nabla \phi_t^{-1}(x) \mid.} \end{equation}\]The marginal probability \(\mathrm{p_t}\) satisfies the continuity equation (see Theorem 1 (Chen et al., 2018)):
\[\begin{equation} \mathrm{\frac{d}{d t} p_t(x) = - \nabla_x \cdot \big( v_t(x)\, p_t(x) \big).}\notag \end{equation}\]To approximate the true vector field \(\mathrm{v_t(x)}\) via a parameterize \(\mathrm{v_{\theta}(t, x)}\), the ideal regression loss is:
\[\begin{equation} \mathrm{\mathcal{L}_{\mathrm{FM}}(\theta)= \mathbb{E}_{t \sim \mathcal{U}[0,1],\, x \sim p_t}\big[ \| v_\theta(t,x) - v_t(x) \|^2 \big]}.\notag \end{equation}\]This is, however, intractable, since both \(\mathrm{p_t}\) and \(\mathrm{v_t}\) are unknown.
Conditional Flow Matching (CFM)
To make the loss more tractable, we introduce a conditioning variable \(\mathrm{x_1\sim p_1}\) and define a conditional flow map \(\mathrm{\psi_t(\cdot \mid x_1)}\) along with a conditional vector field \(\mathrm{v_t(x \mid x_1)}\) satisfying
\[\begin{align} \mathrm{p_t(\cdot\mid x_1)} &\mathrm{= [\psi_t]_\# p_0(\cdot|x_1)=(\psi_t)_\# p_0.}\label{map_psi} \\ \mathrm{\frac{\mathrm{d}}{\mathrm{d}t} \psi_t(x \mid x_1)} &\mathrm{= v_t\big( \psi_t(x \mid x_1) \mid x_1 \big)}, \quad \psi_0(x \mid x_1) = x.\label{flow_eqn}\\ \end{align}\]The unconditional velocity field can then be expressed as a conditional expectation:
\[\begin{equation} \mathrm{v_t(x)=\int v_t(x \mid x_1) \dfrac{p_t(x\mid x_1) q(x_1)}{p_t(x)}dx_1}.\notag \end{equation}\]Recall that \(\mathrm{\psi_t}\) pushes the prior distribution from $\mathrm{p_0}$ to $\mathrm{p_t(\cdot\mid x_1)}$ in \eqref{map_psi}. We can re-define the CFM loss:
\[\begin{align} \mathrm{\mathcal{L}_{\mathrm{CFM}}(\theta)}&\ = \ \ \ \mathrm{\mathbb{E}_{t,\, x_1\sim p_1,\ x \sim p_t(\cdot|x_1)}\big[ \| v_\theta(t,x) - v_t(x\mid x_1) \|^2 \big]} \notag\\ &\mathrm{\overset{\text{Eq.}\eqref{map_psi}}{=}\mathbb{E}_{t,\, x_1\sim p_1,\, x_0 \sim p_0}\Big[\big\|v_\theta\big(t, \psi_t(x_0 \mid x_1)\big)- v_t\big( \psi_t(x \mid x_1) \mid x_1 \big)\big\|^2\Big]}\notag \\ &\mathrm{\overset{\text{Eq.}\eqref{flow_eqn}}{=}\mathbb{E}_{t,\, x_1\sim p_1,\, x_0 \sim p_0}\Big[\big\|v_\theta\big(t, \psi_t(x_0 \mid x_1)\big)- \frac{\mathrm{d}}{\mathrm{d}t} \psi_t(x_0 \mid x_1)\big\|^2\Big].} \notag \\ \end{align}\]By regressing \(\mathrm{v_{\theta}}\) to match the conditional vector field, we obtain an unbiased estimator of the FM loss.
Special Flow Maps
Consider a map \(\mathrm{\psi_t(x\mid x_1)} \mathrm{=\sigma_t(x_1) x + \mu_t(x_1)}\). Taking time gradient and combining Eq.\eqref{flow_eqn}, we have
\[\begin{align} \mathrm{\dfrac{d }{dt}\psi_t(x\mid x_1)} &\mathrm{=\sigma_t'(x_1) x + \mu_t'(x_1)=v_t\big( \psi_t(x \mid x_1) \mid x_1 \big)}. \notag \\ \end{align}\]Replacing $\mathrm{\psi_t(x \mid x_1)}$ with $\mathrm{x}$, s.t. \(\mathrm{\psi_t(x \mid x_1):=\dfrac{x-\mu_t(x_1)}{\sigma_t(x_1)}}\), we have
\[\begin{align} \mathrm{v_t\big(x \mid x_1 \big)} &\mathrm{=\sigma_t'(x_1) \bigg(\dfrac{x-\mu_t(x_1)}{\sigma_t(x_1)}\bigg) + \mu_t'(x_1)}. \label{vector_field_formula} \\ \end{align}\]Connections to Diffusion Models: For VE-SDE (Song et al., 2021), we have \(\mathrm{p_t(x)=N(x\mid x_1, \sigma_{1-t}^2I)},\) the conditional vector field follows \(\mathrm{v_t(x\mid x_1)=-\frac{\sigma_{1-t}'}{\sigma_{1-t}}(x-x_1)}\) via Eq.\eqref{vector_field_formula}. For VP-SDE, the conditional probability follows \(\begin{equation} \mathrm{p_t(x \mid x_1) = N\!\left( x \,\middle|\, \alpha_{1-t} x_1,\, (1 - \alpha_{1-t}^2) I \right)}\notag \end{equation}\), where \(\mathrm{\alpha_t = e^{-\tfrac{1}{2}\int_0^t \beta(s)\,ds}}\). The vector field can be derived in the same way.
Connections to Optimal Transport (OT): Consider the OT flow map:
\[\begin{equation}\boxed{\mathrm{\psi_t(x\mid x_1)=(1-t)x+tx_1}}.\notag\end{equation}\]which corresponds to a displacement map \(\mathrm{p_t=[(1-t)id+t\psi]_* p_0}\). The conditional vector field follows \(\mathrm{v_t(x\mid x_1)=\dfrac{x_1-x}{1-t}}\). The simplified CFM loss function follows that
\[\begin{align} \boxed{\mathrm{\mathcal{L}_{\mathrm{CFM-OT}}(\theta)=\mathbb{E}_{t,\, x_1\sim p_1,\, x_0 \sim p_0}\Big[\big\|v_\theta\big(t, \psi_t(x_0 \mid x_1)\big)- (x_1-x_0)\big\|^2\Big]}}. \notag \\ \end{align}\]Network Parameterization
In diffusion models, noise prediction (Song et al., 2021) learns to predict the added noise \(\mathrm{v_t(x \mid x_0)=p_t(x\mid x_0)}\), while data prediction (Karras et al., 2022) learns to recover the clean data \(\mathrm{v_t(x \mid x_1)=p_t(x\mid x_1)}\) directly. They’re mathematically equivalent, but the denoiser view often makes training more stable and easier to control.
Discrete State Spaces
Problem setup
Consider a sequence \(\mathrm{x=\{x^1, \cdots, x^d\}\in \mathcal{S}}\), where $\mathcal{S}$ is the discrete state space, $\mathrm{x^i\in \mathcal{V}}$ is a token or coordinate and \(\mathcal{V}\) is a vocabulary \(\mathrm{\{1, 2, \cdots, V\}}\). We define the sequence-level \(\mathrm{\delta(x,y)=1}\) if \(\mathrm{x=y}\) and 0 otherwise. It is also used in token-level s.t. \(\mathrm{\delta(x^i, y^i)}\) for some \(\mathrm{x^i, y^i\in \mathcal{V}}\).
Continuous-time Markov Chain (CTMC)
For a CTMC, a random variable \(\mathrm{(X_t)_{0\leq t\leq 1}}\) induces a transition kernel \(\mathrm{p_{t+h\mid t}}\) defined as
\[\begin{align} &\mathrm{p_{t+h\mid t}(y\mid x):=\mathbb{P}(X_{t+h}=y\mid X_t=x)=\delta(y, x)+h v_t(y, x)+o(h), \quad \mathbb{P}(X_0=x)=p(x)}, \notag \end{align}\]where $\mathrm{v_t(y, x)}$ denotes the transition rate or velocity field from state \(\mathrm{x\in \mathcal{S}}\) to \(\mathrm{y\in \mathcal{S}}\):
\[\begin{align} &\mathrm{v_t(y, x)\geq 0 \text{ for all } y\neq x, \text{ and } \sum_y v_t(y, x)=0.} \label{u_limit} \end{align}\]The marginal probability \(\mathrm{p_t}\) for the random variable \(\mathrm{(X_t)_{0\leq t\leq 1}}\) satisfy the Kolmogorov forward equation
\[\begin{align} \mathrm{\dfrac{d}{dt}p_t(y)}&\mathrm{=\sum_x v_t(y, x)p_t(x)} \label{v_def} \\ &\mathrm{=\sum_{x\neq y} v_t(y, x)p_t(x) + v_t(y, y)p_t(y)} \notag \\ &\mathrm{\overset{\eqref{u_limit}}{=}\underbrace{\sum_{x\neq y} v_t(y, x)p_t(x)}_{\text{incoming flux}}-\underbrace{\sum_{x\neq y} v_t(x, y)p_t(y)}_{\text{outgoing flux}}}. \notag \end{align}\]State Transitions with At-most One Token
Note that naïve transitions from \(\mathrm{x}\) to all possible states \(\mathrm{y}\) results in a huge output dimension \({\mathrm{\textbf{V}^d}}\). we introduce factorized velocities that only allow transitions affecting at most one token:
\[\begin{align} &\mathrm{v_t(y, x)=\sum_i \delta(y^{\bar i}, x^{\bar i}) v_t^i(y^i, x)}, \label{factor_u} \end{align}\]where \(\mathrm{\bar i=(1, \cdots, i-1, i+1, \cdots, d)}\). It thus suffices to model \(\mathrm{v_t^i(y^i, x)}\) instead of \(\mathrm{v_t(y, x)}\) and the modeling complexity is significantly reduced from \({\mathrm{\textbf{V}^d}}\) to \({\mathrm{\textbf{V}d}}\).
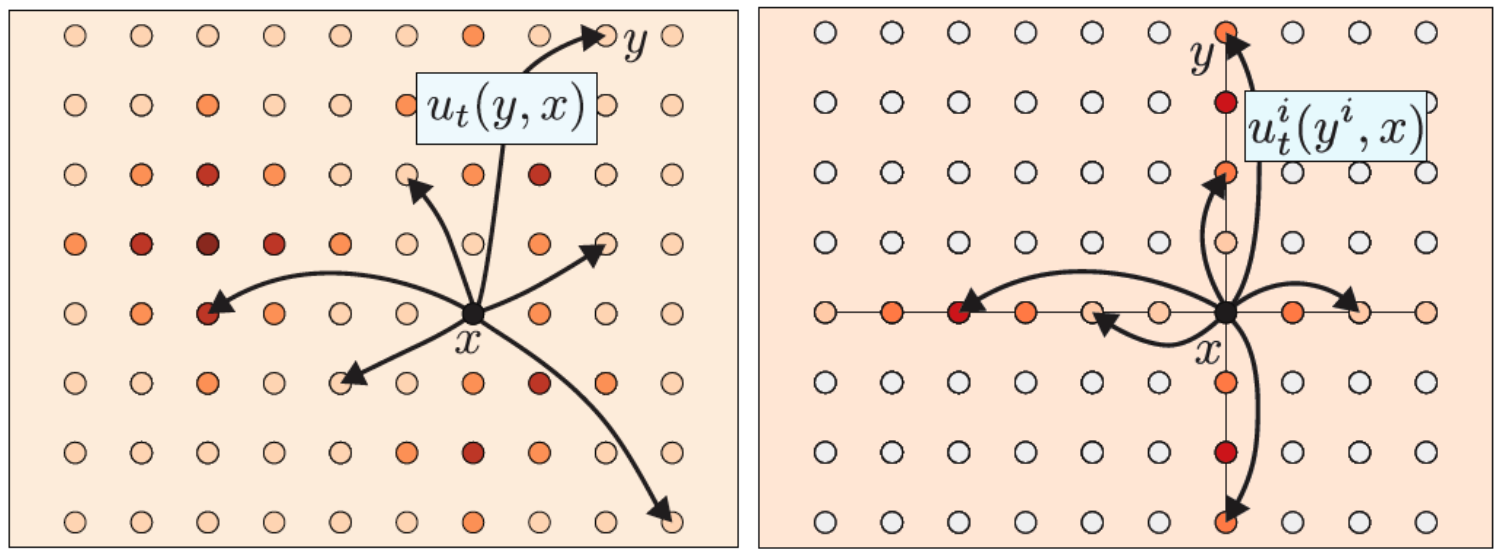
Given \(\mathrm{X_0\sim p_0}\) and the factorized paths and velocities, we can sample \(\mathrm{X_t}\) using the Euler method
\[\begin{align} \mathrm{\mathbb{P}(X_{t+h}=y\mid X_t=x)}&=\mathrm{\delta(y, x)+h v_t(y, x) +o(h)} \notag \\ &\overset{\eqref{factor_u}}{=}\mathrm{\delta(y, x)+h \sum_i \delta(y^{\bar i}, x^{\bar i}) v_t^i(y^i, x) + o(h)} \notag \\ &=\prod_i \bigg[\mathrm{\delta(y^i, x^i)+v_t^i(y^i, x) + o(h)}\bigg], \notag \end{align}\]where the last equality follows from \(\mathrm{\prod_i (a^i + hb^i)=\prod_i a^i + h\sum_i \big(\prod_{j\neq i} a^j\big)b^i + o(h)}\).
Conditional Velocity
Analogous to the continuous case, (Gat et al., 2024) introduced the conditional velocity field s.t.
\[\begin{align} \mathrm{v_t(y, x)=\sum_{x_0,x_1} v_t(y, x\mid x_0, x_1)p_{0, 1\mid t}(x_0, x_1 \mid x)=\mathbb{E}[v_t(y, X_t\mid X_0, X_1)\mid X_t=x]}, \notag \\ \end{align}\]where \(\mathrm{p_{0, 1\mid t}(x_0, x_1\mid x)=\dfrac{p_{t\mid 0, 1}(x\mid x_0, x_1) p_{X_0, X_1}(x_0, x_1)}{p_t(x)}}\).
The factorized conditional path assumes that
\[\begin{align} \mathrm{p_{t\mid 0, 1} (x\mid x_0, x_1)}&\mathrm{=\prod_i p_{t\mid 0, 1}^i (x^i \mid x_0, x_1)}, \notag \\ \end{align}\]where each \(\mathrm{p_{t\mid 0, 1}^i (x^i \mid x_0, x_1)}\) follows an interpolation schedule \(\mathrm{(\kappa_t)_{t\in[0, 1]}}\) and \(\mathrm{\kappa_0=0, \kappa_1=1}\)
\[\begin{align} &\boxed{\mathrm{p_{t\mid 0, 1}^i (x^i \mid x_0, x_1)=(1-\kappa_t)\delta(x^i, x_0^i)+\kappa_t \delta(x^i, x_1^i)}}. \label{mixture_entry} \end{align}\]A random variable \(\mathrm{X_t^i\sim p_{t\mid 0, 1}^i}\) follows
\[\begin{align} \boxed{ \mathrm{ X_t^i = (1 - B_t)\,x_0^i + B_t\,x_1^i, \qquad B_t \sim \mathrm{Bernoulli}(\kappa_t). } } \end{align}\]The dynamics of the conditional marginal probability \(\mathrm{p_t^i}\) then satisfies (Lipman et al., 2024)
\[\begin{align} \mathrm{\dfrac{d}{dt} p_{t\mid 0, 1}^i(y^i\mid x_0, x_1)}&\overset{\eqref{mixture_entry}}{=}\mathrm{\dot{\kappa_t}\bigg[\delta(y^i, x_1^i)-\delta(y^i, x_0^i)\bigg]} \notag \\ &\overset{\eqref{mixture_entry}}{=}\mathrm{\dot{\kappa_t}\bigg[\delta(y^i, x_1^i)-\dfrac{p_{t\mid 0, 1}^i(y^i\mid x_0, x_1)-\kappa_t\delta(y^i, x_1^i)}{1-\kappa_t}\bigg]} \notag \\ &=\mathrm{\frac{\dot{\kappa_t}}{1-\kappa_t}\bigg[\delta(y^i, x_1^i)-p_{t\mid 0, 1}^i(y^i\mid x_0, x_1)\bigg]} \notag \\ &=\mathrm{\sum_{x^i}\frac{\dot{\kappa_t}}{1-\kappa_t}\bigg[\delta(y^i, x_1^i)-\delta(y^i, x^i)\bigg]p_{t\mid 0,1}^i(y^i\mid x_0, x_1)}. \notag \\ \end{align}\]Thus, the conditional velocity follows by Eq.\eqref{v_def}
\[\begin{align} \boxed{\mathrm{v_t^i(y^i, x^i\mid x_0, x_1)=\frac{\dot{\kappa_t}}{1-\kappa_t}\bigg[\delta(y^i, x_1^i)-\delta(y^i, x^i)\bigg]}}. \notag \\ \end{align}\]However, constructing probability-preserving velocities remains challenging and typically requires additional learning of \(\mathrm{p_{0\mid t}^i}\) (Lipman et al., 2024).
Velocity Parameterization
\[\begin{align} \mathrm{v_t(y, x)}&=\mathrm{\sum_{x_0,x_1} v_t(y, x\mid x_0, x_1)p_{0, 1\mid t}(x_0, x_1 \mid x)} \notag \\ &=\mathrm{\sum_{x_1^i} v_t(y, x\mid x_0, x_1)p^i_{1\mid t}(x_1^i \mid x)}, \notag \\ \end{align}\]where \(\mathrm{p^i_{1\mid t}(x_1 \mid x)=\sum_{x_0, x_1^{\bar i}} p_{0, 1\mid t}(x_0, x_1 \mid x)=\mathbb{E}\big[\delta(x_1^i, X_1^i)\mid X_t=x\big]}\).
Hence, one may learn \(\mathrm{v_t^i(y^i, x)}\) via a parametrized model \(\mathrm{p_{1\mid t}^{\theta, i}(x_1^i\mid x)}\) as the data prediction. A suitable conditional matching loss is
\[\begin{align} \mathrm{\mathcal{L}_{CM}(\theta)=\mathbb{E}_{t, X_0, X_1, X_t} D_{X_t}\bigg(\delta(\cdot, X_1^i), p_{1\mid t}^{\theta, i}(\cdot \mid X_t)\bigg)}. \notag \\ \end{align}\]Citation
@misc{deng2025flowmatching,
title ={{Flow Matching: A Minimal Guide}},
author ={Wei Deng},
journal ={waynedw.github.io},
year ={2025},
howpublished = {\url{https://www.weideng.org/posts/flow_matching/}}
}
- Lipman, Y., Chen, R. T. Q., Ben-Hamu, H., Nickel, M., & Le, M. (2023). Flow Matching for Generative Modeling. ICLR.
- Lipman, Y., Havasi, M., Holderrieth, P., Shaul, N., Le, M., Karrer, B., T. Q. Chen, R., Lopez-Paz, D., Ben-Hamu, H., & Gat, I. (2024). Flow Matching Guide and Code.
- Chen, R. T. Q., Rubanova, Y., Bettencourt, J., & Duvenaud, D. (2018). Neural Ordinary Differential Equations. NeurIPS.
- Song, Y., Sohl-Dickstein, J., P. Kingma, D., Kumar, A., Ermon, S., & Poole, B. (2021). Score-Based Generative Modeling through Stochastic Differential Equations. International Conference on Learning Representations (ICLR).
- Karras, T., Aittala, M., Aila, T., & Laine, S. (2022). Elucidating the Exploratory Design Space of Diffusion-Based Generative Models. NeurIPS.
- Gat, I., Remez, T., Shaul, N., Kreuk, F., T. Q. Chen, R., Synnaeve, G., Adi, Y., & Lipman, Y. (2024). Discrete Flow Matching. NeurIPS.