Generative Transformer with Enigmatic Orders
Image synthesis via transformers
A naïve way to process images with transformers is to flatten them into 1D token sequences and train an autoregressive model. However, this leads to long sequences — especially for high-resolution images — making it hard to capture spatial correlations and causing high computational cost and slow inference.
To learn the spacial correlations more efficiently, MaskGIT (Chang et al., 2022) leverages the codebook from VQ-VAE (van den Oord et al., 2017) and adopted a bi-direction transformer decoder with parallel non-autoregressive decoding to speed-up the inference.
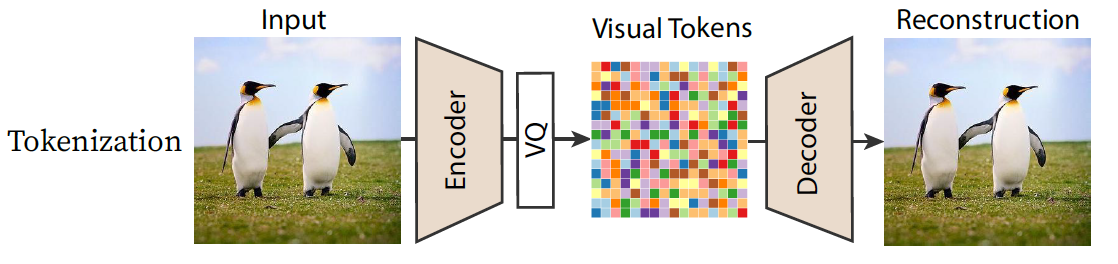
Vector Quantized Variational AutoEncoder (VQ-VAE)
VQ-VAE (van den Oord et al., 2017) (Razavi et al., 2019) aims to represent an image as a sequence of discrete token indices. Given an encoder and a learnable codebook of embeddings $\mathrm{\{e_j\}}$, the VQ block utilizes an encoder to map each image patch to a feature map to find the index of the nearest codebook vector in the codebook.
\[\begin{align} \mathrm{\text{Quantize}(Encoder(x)) = e_k, \quad \text{where} \quad k = \arg\min_j \| Encoder(x) - e_j \|}.\notag \end{align}\]The VQ block can be implementated as follows Code:
# Initialize the codebook as an embedding matrix
self.embedding = nn.Embedding(num_embeddings, embedding_dim)
# Compute L2 distances between encoded vectors z and each codebook embedding (||a - b||^2)
distances = (
torch.sum(z ** 2, dim=-1, keepdim=True) # ||a||²
+ torch.sum(self.embedding.weight.t() ** 2, dim=0, keepdim=True) # ||b||²
- 2 * torch.matmul(z, self.embedding.weight.t()) # -2⟨a, b⟩
)
# Find the nearest codebook vector for each encoded input
encoding_indices = torch.argmin(distances, dim=-1)
# Retrieve quantized vectors from the codebook using the nearest indices
z_q = self.embedding(encoding_indices)
With a well-optmized VQ block, MaskGIT introduces a novel image reconstruction pipeline that models discrete visual tokens.
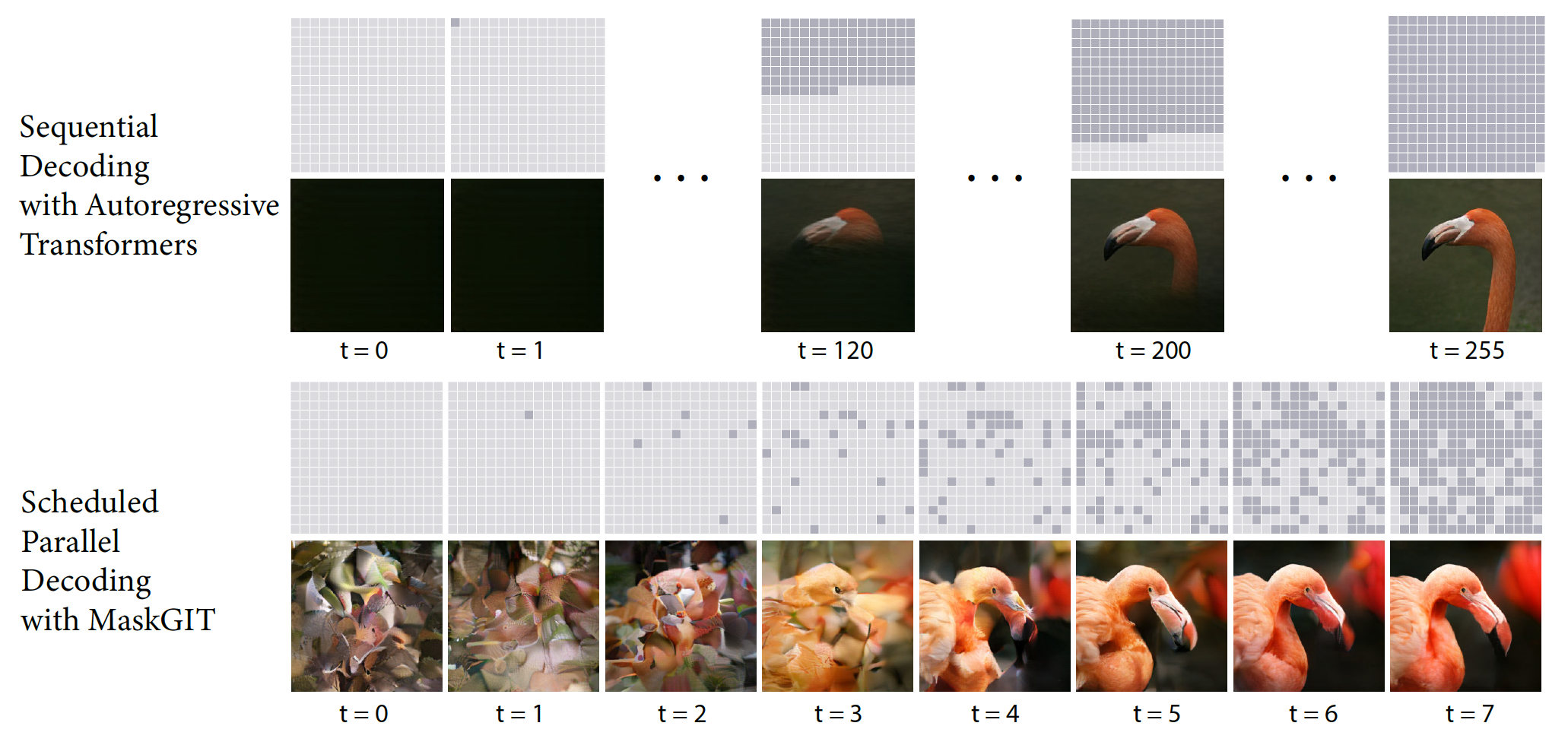
Parallel Decoding
Autoregressive generation is prohibitively slow for high-resolution images. To address this, MaskGIT abandons the autoregressive formulation and instead leverages bidirectional self-attention — similar to BERT (Devlin et al., 2019) — to enable generation in all directions. In each iteration, the model predicts all masked tokens in parallel and retains only the most confident ones for the next step.
Citation
@misc{deng2025_generative_transformer,
title ={{Generative Transformer with Enigmatic Orders}},
author ={Wei Deng},
journal ={waynedw.github.io},
year ={2025},
howpublished = {\url{https://www.weideng.org/posts/generative_transformer/}}
}
- Chang, H., Zhang, H., Jiang, L., Liu, C., & Freeman, W. T. (2022). MaskGIT: Masked Generative Image Transformer. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
- van den Oord, A., Vinyals, O., & Kavukcuoglu, K. (2017). Neural Discrete Representation Learning. Advances in Neural Information Processing Systems (NeurIPS).
- Razavi, A., van den Oord, A., & Vinyals, O. (2019). Generating Diverse High-Fidelity Images with VQ-VAE-2. Advances in Neural Information Processing Systems (NeurIPS).
- Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. NAACL-HLT.