Power Sampling in LLMs
How a training/verifier/data-free sampler outperforms GRPO
GRPO (Shao et al., 2024) has become a dominant RL method for improving reasoning in LLMs. However, it requires expensive training, hyperparameter tuning, and building ad-hoc reward functions, which often reduces sample diversity and generalization ability. A natural question is: Can we unlock the same reasoning performance without costly RL training?
Sub-Optimal Sampling
Our goal is to sample high-likelihood trajectories \(\mathrm{p(x_{0:T})}\). Since we don’t have look-ahead oracles, the likelihood is often approximated by autoregressive property:
\[\mathrm{p(x_{0:T})=\Pi_{t=0}^T p(x_t\mid x_{<t})}.\]Despite the simplicity, decoding locally may be only sub-optimal. Consider a simple example of a length-2 sentence with the token vocabulary of \(\{a, b\}\). The sequence probabilies become
\[\begin{equation} \mathrm{p(aa)=0, \ \ p(ab)=0.45, \ \ p(ba)=0.25, \ \ p(bb)=0.3},\notag \end{equation}\]where we know that \(\mathrm{p(x_0=a)=0.45, p(x_0=b)=0.55}.\) In this example, decoding the token \(\mathrm{b}\) looks like the optimal solution, which seems unreasonable since \(\mathrm{p(ab)}\) has the highest probability.
Power Sampling
To sample \(\mathrm{p(ab)}\), (Karan & Du, 2026) proposed a simple recipe by sampling the power distribution \(\mathrm{p^{\alpha}}\):
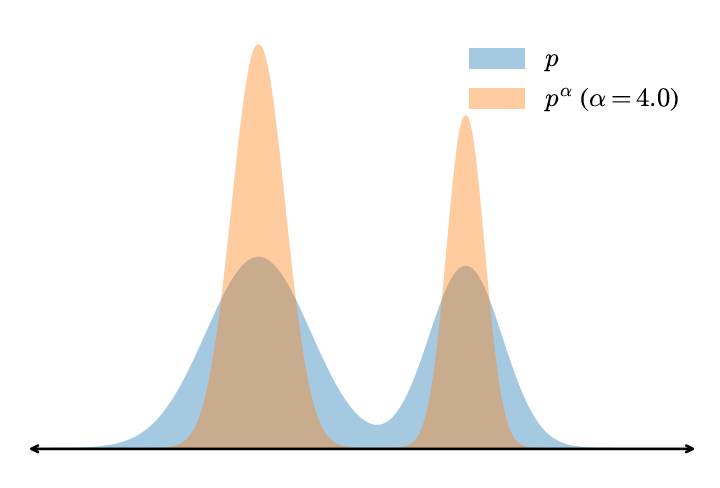
Take the above example, if we choose \(\mathrm{\alpha=2.0}\), we have
\[\begin{equation} \mathrm{p_{\text{power}}(x_0=a)\propto 0.45^2=0.2025 > p_{\text{power}}(x_0=b)\propto 0.25^2 + 0.3^2=0.1525}.\notag \end{equation}\]The sub-optimal decoding issue is easily solved by sampling from a sharpening distribution \(\mathrm{p^2}\). By contrast, the well-known low-temperature strategy fails in this case
\[\begin{equation} \mathrm{p_{\text{low-temperature}}(x_0=a)\propto (0+0.45)^2=0.2025 < p_{\text{power}}(x_0=b)\propto (0.25 + 0.3)^2=0.3025}.\notag \end{equation}\]The above example shows that \(\mathrm{p^{\alpha}}\) motivates future high-likelihood trajectories.
Metropolis-Hastings
For a general length, we first set a block size \(\mathrm{B}\), e.g. 192, to save computations and denote \(\mathrm{\pi_k(x_{0:kB})\propto p(x_{0:kB})^\alpha}\). To sample from \(\mathrm{\pi_{k+1}}\), (Karan & Du, 2026) proposed to first initialize a base sample \(\mathrm{x^{(0)}\rightarrow x}\):
\[\mathrm{x_t^{(0)}\sim p_{\text{proposal}}(x_t\mid x_{<t})} \quad \text{for} \ \ \mathrm{kB+1\leq t \leq (k+1)B}\]where \(\mathrm{p_{\text{proposal}}}\) is a temperature-\(\mathrm{1/\alpha}\) sampler from the base model.
Next for a random \(\mathrm{m\in \{1, 2, \cdots, (k+1)B\}}\), we accept the new sample \(\mathrm{x'}\)
\[\mathrm{x_t'\sim p_{\text{proposal}}(x_t\mid x_{<t})} \quad \text{for} \ \ \mathrm{m\leq t \leq (k+1)B}\]with a probability \(\mathrm{1\wedge A(x', x)}\) via the Metropolis-Hastings algorithm and repeat \(\mathrm{N_{\text{MCMC}}}\) times
Reasoning Performance on Math500
Empirically, power sampling significantly improves over the base model and achieves single-shot reasoning performance comparable to GRPO, without any post-training. Moreover, because it preserves sampling diversity, it delivers stronger Pass@k performance across multiple samples.
\[\mathrm{A(x', x) \leftarrow \min \left\{ 1,\, \frac{\pi_k(x')}{\pi_k(x)} \cdot \frac{p_{\mathrm{proposal}}(x \mid x')}{p_{\mathrm{proposal}}(x' \mid x)} \right\}.}\]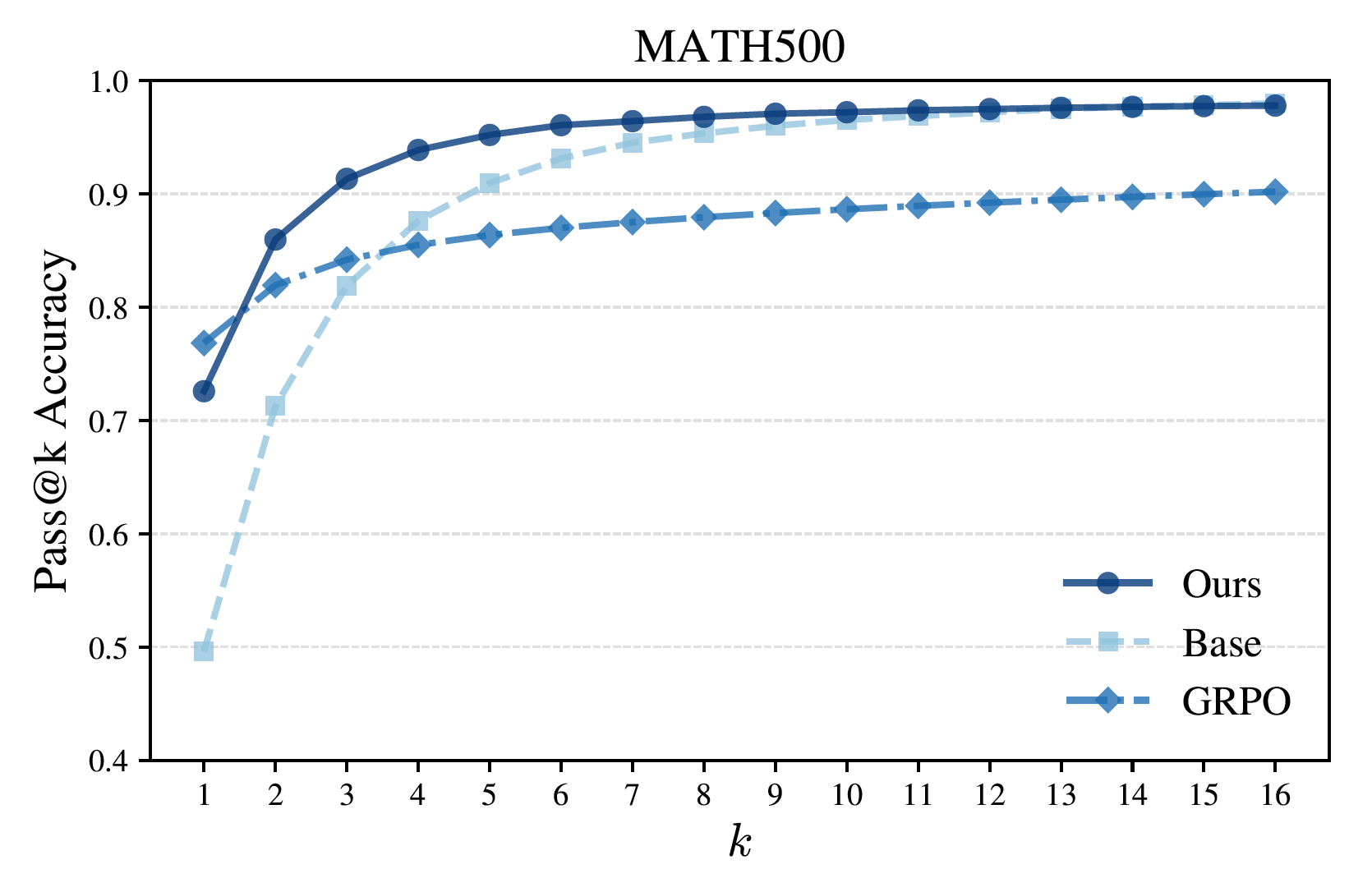
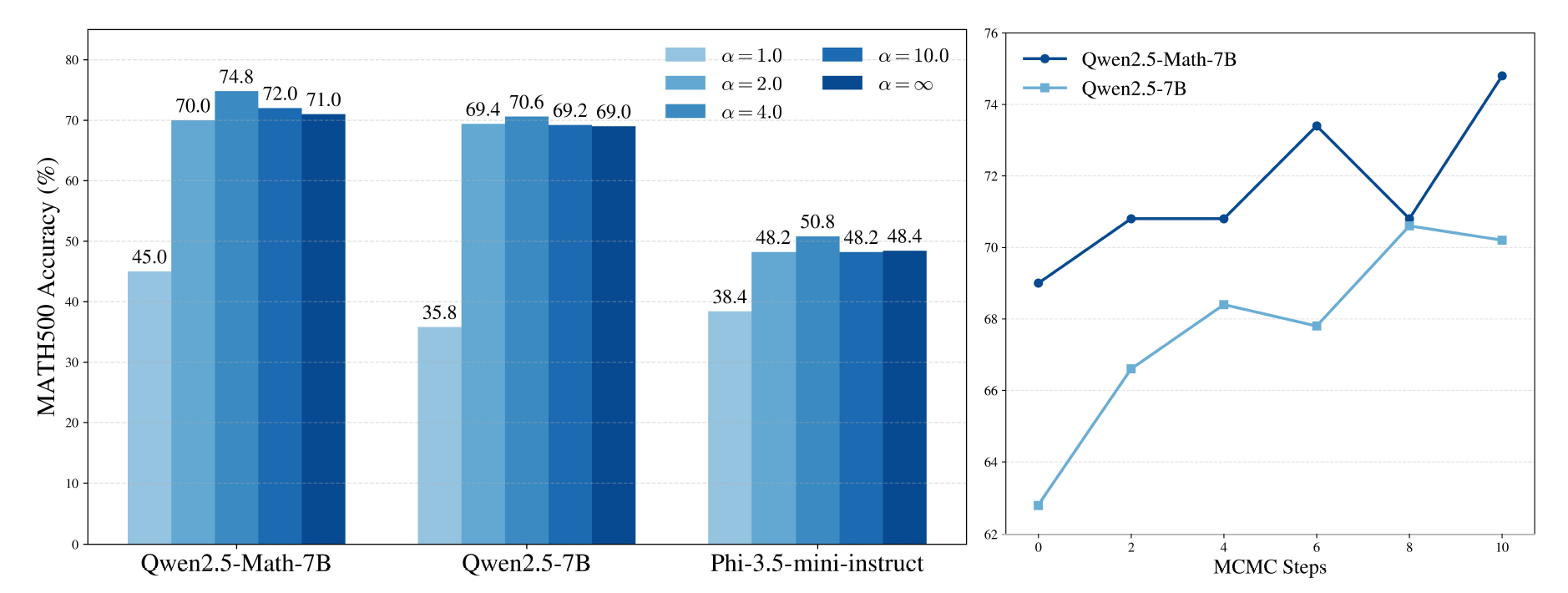
The following shows the impact of $\mathrm{\alpha, N_{\text{MCMC}}}$ where $\mathrm{\alpha, N_{\text{MCMC}>1}}$ significantly improves the performance.
Citation
@misc{deng2026_power,
title ={{Power Sampling in LLMs}},
author ={Wei Deng},
journal ={waynedw.github.io},
year ={2026},
howpublished = {\url{https://www.weideng.org/posts/power_samplers/}}
}
- Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y. K., Wu, Y., & others. (2024). DeepseekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. ArXiv Preprint ArXiv:2402.03300.
- Karan, A., & Du, Y. (2026). Reasoning with Sampling: Your Base Model is Smarter Than You Think. ICLR.