Couplings and Monte Carlo Methods (I)
A family of techniques to understand the convergence of random variables.
A coupling of two random variables/ vectors represents a joint distribution, where the marginal distributions are denoted by $p$ and $q$, respectively. Any joint distributions of $p$ and $q$ define a valid coupling. Although there are infinitely many of them, some of them are quite special and may facilitate our analysis.
Maximal Coupling
Total variation distance is defined as follows
\begin{equation}\notag \mathrm{\forall A\in X, \quad |p-q|_{\text{TV}}=\sup_{X\in A} \mathbb{P}(X\in A) - \mathbb{P}(Y\in A),} \end{equation} where $\mathrm{X}$ and $\mathrm{Y}$ are random variables defined on the state space $\mathbb{X}$ with measurable set $X$. Note that for any measurable set $\mathrm{A\in X}$, the follow inequality always holds
$\mathrm{\mathbb{P}(X\in A)- \mathbb{P}(Y\in A)=\mathbb{P}(X\in A \cap X\neq Y)- \mathbb{P}(Y\in A \cap X\neq Y)\leq \mathbb{P}(X\neq Y)}$.
There exists one pair of $\mathrm{(X,Y)}$ such that the above inequality holds. Any coupling that satisfies this property is known as maximal coupling.
Denoting by $\mathrm{\nu=p-q}$ the zero-mass measure, there is a set $D$ according to the Hahn-Jordan decomposition such that $\mathrm{\nu^{+}=(p-q)(\cdot \cap D)}$ and $\mathrm{\nu^{-}=(q-p)(\cdot \cap D^c)}$ are both positive measures and $\mathrm{\nu=\nu^{+}-\nu^-}$.
Notably, it is clear that $\mathrm{D=\{x:\ p(x)\geq q(x)\}}$. It follows that $\mathrm{\sup_{A\in {X}} \mathbb{P}(X\in A)- \mathbb{P}(Y\in A)=\sup_{A\in {X}}\nu(A)=\nu(D)=\mathbb{P}(X\in D)-\mathbb{P}(Y\in D)}$. We have
\[\begin{align} \mathrm{\mathbb{P}(X\in D)-\mathbb{P}(Y\in D)}&\mathrm{=\int_{\{x:\ p(x)\geq q(x)\}} p(x) d x - \int_{\{x:\ p(x) \geq q(x)\}} q(x) d x} \nonumber\\ &\mathrm{=\int_{\{x:\ p(x)< q(x)\}} q(x) d x - \int_{\{x:\ p(x) < q(x)\}} p(x) d x.}\nonumber \end{align}\]
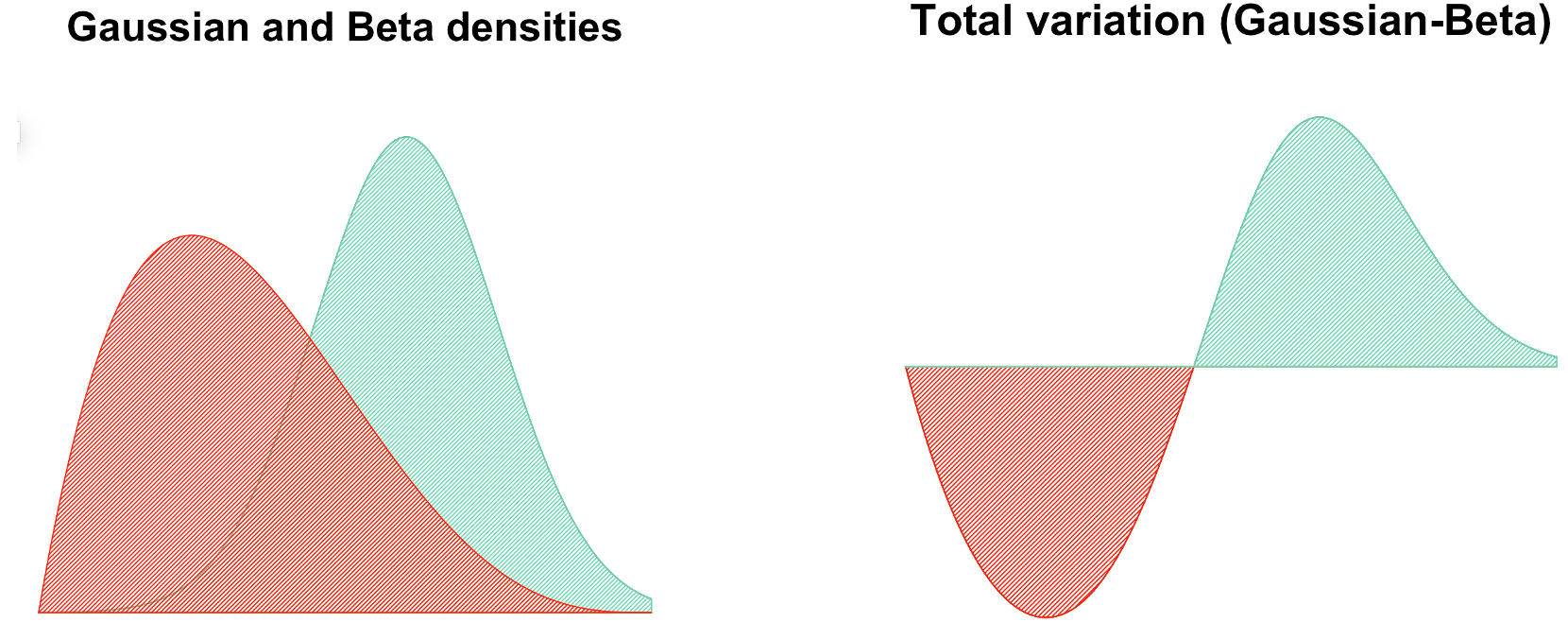
Summing up the above equations and combining $|a-b|=a+b-2 a\wedge b$, we can obtain the area between the two pdf curves (Jacob, 2021)
\begin{equation}\notag \mathrm{|p-q|_{\text{TV}}=\frac{1}{2} \int |p(x)- q(x)| d x = 1-\int \min \{p(x), q(x) \} dx.} \end{equation}
In the end, we can summarize the different formulations of total variation
\[\begin{align}\notag \mathrm{\|p-q\|_{\text{TV}}}&\mathrm{=\sup \mathbb{P}(X\in A)- \mathbb{P}(Y\in A)}\\ &\mathrm{=\frac{1}{2}\int |p(x)- q(x)| d x}\notag\\ &\mathrm{=1-\int \min\{p(x), q(x)\} d x}\notag\\ &\mathrm{=\inf_{(X,Y)\in \text{coupling}(p, q)} \mathbb{P}(X\neq Y).}\notag \end{align}\]Applications
Suppose $\mathrm{(X_i)}$ follow an (independent) binomial distribution $\mathrm{Binomial(\lambda, N)}$ and $\mathrm{(Y_i)}$ follow an (independent) Poisson distribution $\mathrm{Poisson(\lambda)}$. Next, we couple $\mathrm{X_i}$ and $\mathrm{Y_i}$ maximally. The overlap mass is equal to $\mathrm{(1-\lambda)\wedge e^{-\lambda} + \lambda \wedge \lambda e^{-\lambda}=1-\lambda+\lambda e^{-\lambda}}$. That means $\mathrm{\mathbb{P}(X_i\neq Y_i)=\lambda(1-e^{-\lambda})\leq \lambda^2}$.
Replace $\lambda$ with $\lambda/N$, we have \begin{equation}\notag \mathrm{\mathbb{P}\left(\frac{\sum_{i=1}^N X_i-\sum_{i=1}^N Y_i}{N}\right)\leq \frac{\lambda^2}{N},} \end{equation} where implies that given a large N and a fixed $\mathrm{\lambda}$, Poisson distribution approximates the binomial distribution.
Convergence rates
By assuming $\mathrm{(Y_t)}$ is simulated from the stationary distribution in the beginning, we can introduce a coupling inequality such that
\begin{equation}\notag \mathrm{L(X_t)-{L}(Y_t)| \leq \mathbb{P}(\tau>t),} \end{equation} where $\tau$ is a random variable that enables $\mathrm{X_t=Y_t}$ and is also known as ‘‘meeting time’’. The equality can be achieved given the maximal coupling but the contruction may differ in different problems. In addition, meeting exactly sometimes is quite restricted; it is enough to consider close enough chains.
Synchronous Coupling
Synchronous coupling models the contraction of a pair of trajectories and can be used to prove the convergence of stochastic gradient Langevin dynamics for strongly log-concave distributions.
Let $\mathrm{\theta_k\in \mathbb{R}^d}$ be the $k$-th iterate of the following stochastic gradient Langevin algorithm. \begin{align}\notag \mathrm{\theta_{k+1}=\theta_k -\eta \nabla \widetilde f(\theta_k)+\sqrt{2\tau\eta}\xi_k,} \end{align} where $\eta$ is the learning rate, $\tau$ is the temperature, $\mathrm{\xi_k}$ is a standard $d$-dimensional Gaussian vector, and $\mathrm{\nabla \widetilde f(\theta)}$ is an unbiased estimate of the exact gradient $\mathrm{\nabla f(\theta)}$.
Assumptions
Smoothness We say $\mathrm{f}$ is $\mathrm{L}$-smooth if for some $\mathrm{L>0}$ \begin{align}\label{def:strong_convex} \mathrm{f(y)\leq f(x)+\langle \nabla f(x),y-x \rangle+\frac{L}{2}\| y-x \|^2_2\quad \forall x, y\in \mathbb{R}^d.} \end{align}
Strong convexity We say $\mathrm{f}$ is $\mathrm{m}$-strongly convex if for some $\mathrm{m>0}$ \begin{align}\label{def:smooth} \mathrm{f(x)\geq f(y)+\langle \nabla f(y),x-y \rangle + \frac{m}{2} \| y-x \|_2^2\quad \forall x, y\in \mathbb{R}^d.} \end{align}
Bounded variance The variance of stochastic gradient $\mathrm{\nabla \widetilde f(x)}$ is upper bounded such that \begin{align}\label{def:variance} \mathrm{\mathbb{E}[\|\nabla \widetilde f(x)-\nabla f(x)\|^2] \leq \sigma^2 d,\quad \forall x\in \mathbb{R}^d.} \end{align}
A Crude Estimate
Assume assumptions \ref{def:strong_convex}, \ref{def:smooth}, and \ref{def:variance} hold. For any learning rate $\mathrm{\eta \in (0 , 1 \wedge {m}/{L^2} )}$ and $\mathrm{|| \theta_0-\theta_* || \leq \sqrt{d} {D}}$, where $\mathrm{\theta_*}$ is a stationary point. Then
\begin{align}\notag \mathrm{W_2(\mu_k, \pi) \leq e^{-{mk\eta}/{2}} \cdot 2 ( \sqrt{d} {D} + \sqrt{d/m} ) + \sqrt{ 2d (\sigma^2+L^2 G\eta) / m^2},} \end{align}
where $\mathrm{\mu_k}$ denotes the probability measure of $\mathrm{\theta_k}$ and $\mathrm{G:=25(\tau+m {D}^2+\sigma^2)}$.
Proof
Denote $\mathrm{\theta_t}$ as the continuous-time interpolation of the stochastic gradient Langevin dynamics as follows
\begin{align}\notag \mathrm{d \theta_t = - \nabla \widetilde f(\theta_{\eta\lfloor\frac{t}{\eta} \rfloor}) d t + \sqrt{2\tau} d \widetilde W_t,} \end{align}
where $\mathrm{\theta_0=\theta_0}$. For any $\mathrm{k\in \mathbb{N}^{+}}$ and a time $\mathrm{t}$ that satisfies $\mathrm{t=k\eta}$, it is apparent that $\mathrm{\widehat\mu_t={L}({\theta}_t)}$ is the same as $\mathrm{\mu_k={L}(\theta_k)}$, where $\mathrm{L(\cdot)}$ denotes a distribution of a random variable. In addition, we define an auxiliary process $\mathrm{(\beta_t)}$ that starts from the stationary distribution $\mathrm{\pi}$
\begin{align}\notag \mathrm{d \beta_t = - \nabla f(\beta_t) d t + \sqrt{2\tau} d W_t.} \end{align}
Consider Itô’s formula for the sequence of $\mathrm{\frac{1}{2} \| \theta_t - \beta_t \| ^2}$
\[\begin{align}\notag &\ \ \ \mathrm{\frac{1}{2} d \| \theta_t - \beta_t \|^2}\notag\\ &\mathrm{= \langle \theta_t - \beta_t, d \theta_t - d \beta_t \rangle + \mathrm{Tr}[ d^2 \theta_t - d^2 \beta_t ]}\notag\\ &\mathrm{=\langle \theta_t - \beta_t, (\nabla f(\beta_t) -\nabla\widetilde f(\theta_{\eta\lfloor\frac{t}{\eta} \rfloor}) ) d t + \sqrt{2\tau} ( d \widetilde W_t - d W_t ) \rangle + 2\tau \mathrm{Tr}[ d^2 \widetilde W_t - d^2 W_t ].}\notag \end{align}\]Taking $\mathrm{\widetilde W_t=W_t}$ defines a synchronous coupling. Arrange the terms
\[\begin{align}\notag &\ \ \ \mathrm{\frac{1}{2} d \| \theta_t - \beta_t \|^2} \notag\\ &= \mathrm{\langle \theta_t - \beta_t, \nabla f(\beta_t)-\nabla f(\theta_t) \rangle d t+ \langle \theta_t - \beta_t, \nabla f(\theta_{t}) - \nabla f(\theta_{\eta\lfloor\frac{t}{\eta} \rfloor}) \rangle d t}\notag\\ &\qquad \qquad\qquad+ \mathrm{\langle \theta_t - \beta_t, \nabla f(\theta_{\eta\lfloor\frac{t}{\eta} \rfloor}) - \nabla \widetilde f(\widehat \theta_{\eta\lfloor\frac{t}{\eta} \rfloor}) \rangle d t} \notag\\ &\leq \mathrm{- m \| \theta_t - \beta_t \|^2 d t + \frac{m}{4} \| \theta_t - \beta_t \|^2 d t + \frac{1}{m} \| \nabla f(\theta_{t}) - \nabla f(\theta_{\eta\lfloor\frac{t}{\eta} \rfloor}) \|^2 d t} \notag\\ &\qquad\qquad \mathrm{+ \frac{m}{4} \| \theta_t - \beta_t \|\|^2 d t + \frac{1}{m} \| \nabla f(\theta_{\eta\lfloor\frac{t}{\eta} \rfloor}) - \nabla \widetilde f(\widehat \theta_{\eta\lfloor\frac{t}{\eta} \rfloor}) \|^2 d t}\notag\\ &\leq \mathrm{- \frac{m}{2} \| \theta_t - \beta_t \|\|^2 d t + \frac{d\sigma^2}{m} d t +\frac{1}{m} \| \nabla f(\theta_{t}) - \nabla f(\theta_{\eta\lfloor\frac{t}{\eta} \rfloor}) \|^2 d t}\notag\\ &\leq \mathrm{- \frac{m}{2} \| \theta_t - \beta_t \|^2 d t + \frac{d\sigma^2}{m} d t+ \frac{L^2}{m} \| \theta_{t} - \theta_{\eta\lfloor\frac{t}{\eta} \rfloor} \|^2 d t}\notag\\ \end{align}\]where the first inequality follows from $\mathrm{ab\leq (\frac{\sqrt{m}}{2}a)^2+({\frac{1}{\sqrt{m}}}b)^2}$ and the strong-convexity property \ref{def:strong_convex}; in particular, we don’t attempt to optimize the constants of $\mathrm{-\frac{m}{2}}$ for the item $\mathrm{|| \theta_t - \beta_t ||^2}$; the second and third inequalities follow by bounded variance assumption \ref{def:variance} and the smoothness assumption \ref{def:smooth}, respectively.
Now apply Grönwall’s inequality to the preceding inequality and take expectation respect to a coupling $\mathrm{(\theta_t, \beta_t) \sim \Gamma(\widehat\mu_t,\pi)}$ \begin{align}\label{eq:1st_gronwall} \mathrm{\mathbb{E}{ \|\theta_t - \beta_t \|^2}\leq \mathbb{E}{\| \theta_0 - \beta_0 \|^2} e^{-mt}+\frac{2}{m}\int_0^t g(d\sigma^2+ L^2\underbrace{\mathbb{E}{ \| \theta_{s} - \theta_{\eta\lfloor\frac{s}{\eta} \rfloor} \|^2 }}_{I: \text{Discretization error}} g) e^{-(t-s)m} d s. } \end{align}
Plugging some estimate of $I$ into Eq.\eqref{eq:1st_gronwall}, we have \(\begin{align}\notag &\ \ \ \mathrm{\mathbb{E}{ \| \theta_t - \beta_t \|^2}}\\ &\mathrm{\leq \mathbb{E}{ \| \theta_0 - \beta_0 \|^2} e^{-mt}+\frac{2d}{m} (\sigma^2+L^2 G\eta) \int_0^t e^{-(t-s)m} d s}\notag\\ &\mathrm{\leq \mathbb{E}{ \| \theta_0 - \beta_0 \|^2} e^{-mt}+\frac{2d}{m^2} (\sigma^2+L^2 G\eta)}.\notag \end{align}\)
Recall that $\mathrm{\theta_k}$ and $\mathrm{\widehat\theta_{t\eta}}$ have the same distribution $\mathrm{\mu_k}$. By the definition of $\mathrm{W_2}$ distance, we have
\[\begin{align}\notag &\ \ \ \mathrm{W_2(\mu_k, \pi)}\\ &\mathrm{\leq e^{-{mk\eta}/{2}} \cdot W_2(\mu_0, \pi) + \sqrt{ 2d (\sigma^2+L^2 G\eta) / m^2}}\notag\\ &\mathrm{\leq e^{-{mk\eta}/{2}} \cdot 2 (\| \theta_0 - \theta_* \| + \sqrt{d/m} )+ \sqrt{ 2d(\sigma^2+L^2 G\eta) / m^2}}\notag\\ &\mathrm{\leq e^{-{mk\eta}/{2}} \cdot 2 ( \sqrt{d} {D} + \sqrt{d/m} )+ \sqrt{ 2 d(\sigma^2+L^2 G\eta) / m^2}},\notag \end{align}\]where the first inequality follows by applying $\mathrm{\sqrt{| a + b |} \leq \sqrt{| a |} + \sqrt{| b |}}$, the second one follows by an estimate of $\mathrm{W_2(\mu_0, \pi)}$, and the last step follows from the initialization condition.
Remark: How to achieve a sharper upper bound?
- Jacob, P. E. (2021). Couplings and Monte Carlo. Slides.