Ensemble Kalman Filter
A scalable template for high-dimensional time series predictions
Recursive Least Squares
Consider linear regression
$\begin{align} \mathrm{y}=\mathrm{x} \beta + \varepsilon.\label{OLS} \end{align}$
where $\mathrm{y}, \varepsilon\in \mathrm{R}$, $\mathrm{x}\in\mathrm{R}^{1\times d}$, and $\beta\in \mathrm{R}^{d\times 1}$.
Given $n$ observations $(\mathrm{x}_1, \mathrm{y}_1), (\mathrm{x}_2, \mathrm{y}_2), \cdots, (\mathrm{x}_n, \mathrm{y}_n)$, the solution of Eq.\eqref{OLS} follows that
\[\begin{align} \widehat\beta_n = (\mathrm{X}_n^\intercal \mathrm{X}_n)^{-1} \mathrm{X}_n^\intercal \mathrm{Y}_n, \label{solution_n} \end{align}\]where \(\mathrm{X}_n=\begin{bmatrix}\mathrm{x}_1 \\ \mathrm{x}_2 \\ \cdots \\ \mathrm{x}_n \end{bmatrix}\) is a $n\times d$ matrix and \(\mathrm{Y}_n=\begin{bmatrix}\mathrm{y}_1 \\ \mathrm{y}_2 \\ \cdots \\ \mathrm{y}_n \end{bmatrix} \in \mathrm{R}^n\).
Consider online learning when we have a new $\mathrm{x}_{n+1}$, the solution can be updated as follows
\[\begin{align} \widehat\beta_{n+1} &= (\mathrm{X}_{n+1}^\intercal \mathrm{X}_{n+1})^{-1} \mathrm{X}_{n+1}^\intercal \mathrm{Y}_{n+1}\notag\\ &=(\mathrm{P}_{n}^{-1} + \mathrm{x}_{n+1}^\intercal \mathrm{x}_{n+1})^{-1} (\mathrm{X}_{n}^\intercal \mathrm{Y}_{n} + \mathrm{x}_{n+1}^\intercal \mathrm{y}_{n+1})\notag \\ &=\underbrace{(\mathrm{P}_{n}^{-1} + \mathrm{x}_{n+1}^\intercal \mathrm{x}_{n+1})^{-1}}_{\mathrm{P}_{n+1}} \big(\mathrm{P}_{n}^{-1}\widehat\beta_n + \mathrm{x}_{n+1}^\intercal \mathrm{y}_{n+1} \big),\label{decomposition} \end{align}\]where \(\mathrm{P}_n=(\mathrm{X}_{n}^\intercal \mathrm{X}_{n})^{-1}\), the second equality holds by the block matrix multiplication, and the last equality is followed by Eq.\eqref{solution_n}.
Applying the Woodbury matrix identity, the item $\mathrm{P}_{n+1}$ in Eq.\eqref{decomposition} can be simplified
\[\begin{align} \mathrm{P}_{n+1}&=\mathrm{P}_n - \mathrm{P}_n \mathrm{x}_{n+1}^\intercal [\underbrace{1 + \mathrm{x}_{n+1} \mathrm{P}_n \mathrm{x}_{n+1}^\intercal}_{\mathrm{S}_{n+1} \text{, which is a scalar.}}]^{-1} \mathrm{x}_{n+1} \mathrm{P}_n\notag\\ &=\mathrm{P}_n - \mathrm{K}_{n+1} \mathrm{S}_{n+1} \mathrm{K}_{n+1}^\intercal,\label{P_solution} \\ \text{where}\ \ \mathrm{K}_{n+1}&=\mathrm{P}_n \mathrm{x}_{n+1}^\intercal \mathrm{S}_{n+1}^{-1}. \label{def_K} \end{align}\]Combining Eq.\eqref{decomposition} and Eq.\eqref{P_solution}, we have
\[\begin{align} \widehat\beta_{n+1} &= (\mathrm{P}_n - \mathrm{K}_{n+1} \mathrm{S}_{n+1} \mathrm{K}_{n+1}^\intercal) \big(\mathrm{P}_{n}^{-1}\widehat\beta_n + \mathrm{x}_{n+1}^\intercal \mathrm{y}_{n+1} \big) \notag \\ &=\widehat\beta_n - \mathrm{K}_{n+1} \mathrm{S}_{n+1} \mathrm{K}_{n+1}^\intercal \mathrm{P}_{n}^{-1}\widehat\beta_n + \mathrm{P}_n \mathrm{x}_{n+1}^\intercal \mathrm{y}_{n+1} - \mathrm{K}_{n+1} \mathrm{S}_{n+1} \mathrm{K}_{n+1}^\intercal \mathrm{x}_{n+1}^\intercal \mathrm{y}_{n+1} \notag \\ % &\overset{\eqref{def_K}}{=}\widehat\beta_n - \mathrm{K}_{n+1} \mathrm{x}_{n+1}\widehat\beta_n + \mathrm{P}_n \mathrm{x}_{n+1}^\intercal \mathrm{y}_{n+1} - \mathrm{K}_{n+1} \mathrm{S}_n \mathrm{K}_{n+1}^\intercal \mathrm{x}_{n+1}^\intercal \mathrm{y}_{n+1} \notag \\ % &\overset{\eqref{def_K}}{=}\widehat\beta_n - \mathrm{K}_{n+1} \mathrm{x}_{n+1}\widehat\beta_n + \mathrm{P}_n \mathrm{x}_{n+1}^\intercal \mathrm{y}_{n+1} - \mathrm{K}_{n+1} \mathrm{x}_{n+1} \mathrm{P}_{n} \mathrm{x}_{n+1}^\intercal \mathrm{y}_{n+1} \notag \\ &\overset{\eqref{def_K}}{=}\widehat\beta_n - \mathrm{K}_{n+1} \mathrm{x}_{n+1}\widehat\beta_n + \mathrm{K}_{n+1} \mathrm{S}_{n+1} \mathrm{y}_{n+1} - \mathrm{K}_{n+1} \mathrm{x}_{n+1} \mathrm{P}_{n} \mathrm{x}_{n+1}^\intercal \mathrm{y}_{n+1} \notag \\ &=\widehat\beta_n + \mathrm{K}_{n+1} (\mathrm{y}_{n+1} - \mathrm{x}_{n+1}\widehat\beta_n), \notag \\ \end{align}\]where the third equality follow by repeatly using \(\mathrm{K}_{n+1} \mathrm{S}_{n+1} =\mathrm{P}_n \mathrm{x}_{n+1}^\intercal\) in \eqref{def_K} for the right three items and the last equality follows by \(\mathrm{S}_{n+1}=1 + \mathrm{x}_{n+1} \mathrm{P}_n \mathrm{x}_n^\intercal\) above Eq.\eqref{P_solution}.
To summarize, the update scheme for recursive least squares follow that
\[\begin{align} \widehat\beta_{n+1}&=\widehat\beta_n + \mathrm{K}_{n+1} (\mathrm{y}_{n+1} - \mathrm{x}_{n+1}\widehat\beta_n)\notag\\ \mathrm{K}_{n+1}&=\mathrm{P}_n \mathrm{x}_{n+1}^\intercal \mathrm{S}_{n+1}^{-1}\notag \\ \mathrm{P}_{n+1}&=\mathrm{P}_n - \mathrm{K}_{n+1} \mathrm{S}_{n+1} \mathrm{K}_{n+1}^\intercal\notag \\ \mathrm{S}_{n+1}&=1 + \mathrm{x}_{n+1} \mathrm{P}_n \mathrm{x}_{n+1}^\intercal. \notag \end{align}\]Kalman Filter
Kalman Filter (Särkkä, 2023) or state space model are powerful tools in finance for estimating and predicting the state of a system based on incomplete and noisy measurements. It describes the evolution of a system over time in terms of its unobservable states and observable outputs.
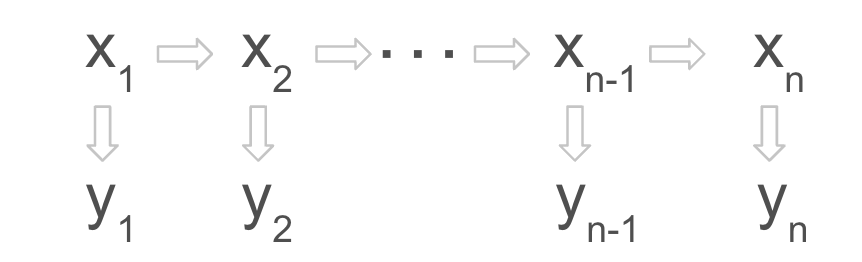
The dynamics and the measurements follow a linear Gaussian model
\[\begin{align} \mathrm{x}_n&=\mathrm{A}_{n-1} \mathrm{x}_{n-1} + \mathrm{w}_{n-1}, \ \ \mathrm{w}_{n-1}\sim \mathrm{N}(0, \mathrm{Q}_{n-1})\notag\\ \mathrm{y}_n&=\mathrm{H}_n\mathrm{x}_n + \mathrm{r}_n, \ \ \mathrm{r}_n \sim \mathrm{N}(0, \mathrm{R}_n) \label{linear_ss}. \end{align}\]where \(\mathrm{x}_n\in\mathrm{R}^d\) is the latent state and \(\mathrm{y}_n\in\mathrm{R}^p\) is the measurement. \(\mathrm{A}_{n-1}\) is the transition matrix and $\mathrm{H}_n$ is the measurement model. Both matrices are assumed to be known or can be estimated through MLE. In weather forecasts, the state and observation dimensions are often large such that $d\geq 10^7$ and $p\geq 10^5$ (Katzfuss et al., 2016).
The probabilistic formulation is
\[\begin{align} \mathrm{P}(\mathrm{x}_n|\mathrm{x}_{n-1})&=\mathrm{N}(\mathrm{x}_n|\mathrm{A}_{n-1} \mathrm{x}_{n-1}, \mathrm{Q}_{n-1}) \notag \\ \mathrm{P}(\mathrm{y}_n|\mathrm{x}_n)&=\mathrm{N}(\mathrm{y}_n|\mathrm{H}_n\mathrm{x}_n, \mathrm{R}_n) \notag. \end{align}\]Assume the filtering distribution given the information up to step $n-1$, where \(n\in \mathrm{N}^+\), follows
\[\begin{align} \mathrm{P}(\mathrm{x}_{n-1}|\mathrm{y}_{1:n-1})&=\mathrm{N}(\mathrm{x}_{n-1}|\mathrm{u}_{n-1}, \mathrm{P}_{n-1}). \label{filter_dist}\\ \end{align}\]Theorem The Bayesian filtering equations \eqref{linear_ss} can be evaluated in a closed-form Gaussian distribution:
\[\begin{align} \mathrm{P(x_n|y_{1:n-1})}&=\mathrm{N(x_n|u_n^-, P_n^-)}\notag \\ \mathrm{P(x_n|y_{1:n})}&=\mathrm{N(x_n|u_n, P_n)}\notag \\ \mathrm{P(y_n|y_{1:n-1})}&=\mathrm{N(y_n|H_n u_n, S_n)}.\notag \end{align}\]The prediction step follows
\[\begin{align} \mathrm{u_n^-} &= \mathrm{A_{n-1} u_{n-1}},\notag\\ \mathrm{P_n^-} &= \mathrm{A_{n-1} P_{n-1} A_{n-1}^\intercal + Q_{n-1}}.\notag \end{align}\]The update step follows
\[\begin{align} \mathrm{S_n} &= \mathrm{H_n P_n^- H_n^\intercal + R_n}\notag\\ \mathrm{K_n} &= \mathrm{P_n^- H_n^\intercal S_n^{-1}} \label{kalman_gain}\\ \mathrm{u_n} &= \mathrm{u_n^- + K_n (y_n - H_n u_n^-)}\notag\\ \mathrm{P_n} &= \mathrm{P_n^- - K_n S_n K_n^\intercal} \notag, \end{align}\]where $\mathrm{K_n}$ is the Kalman gain matrix of size $d\times p$. Note that since storing and inverting the matrix is quite expensive when $d$ or $p$ is large. Approximations are inevitable.
Proof
(I) By Lemma A.1, the joint distribution of $\mathrm{x_n, x_{n-1}}$ given $\mathrm{y_{1:n-1}}$ is
\[\begin{align} &\mathrm{\quad\ P(x_{n-1}, x_n|y_{1:n-1})}\notag\\ &=\mathrm{P( x_n|x_{n-1}) P(x_{n-1}|y_{1:n-1})}\notag\\ &=\mathrm{N(x_n| A_{n-1}x_{n-1}, Q_{n-1}) N(x_{n-1}| u_{n-1}, P_{n-1})}\notag\\ &=\mathrm{N\bigg(\begin{bmatrix}\mathrm{x}_{n-1} \\ \mathrm{x}_n \end{bmatrix}\bigg|u', P'\bigg)},\notag \end{align}\]where
\[\begin{align*} \mathrm{u'}&=\begin{bmatrix}\mathrm{u_{n-1}} \\ \mathrm{A_{n-1} u_{n-1}}\end{bmatrix} \notag \\ \mathrm{P'}&=\begin{bmatrix} \mathrm{P_{n-1}} & \mathrm{P_{n-1} A_{n-1}^\intercal} \\ \mathrm{A_{n-1}P_{n-1}} & \mathrm{A_{n-1} P_{n-1} A_{n-1}^\intercal+ Q_{n-1}} \end{bmatrix}\end{align*}. \notag\]By Lemma A.2, the marginal $\mathrm{x}_n$ follows that
\[\begin{align} \mathrm{P(x_n|y_{1:n-1})=N(x_n|u_n^-, P_n^-),} \label{xk_given_y_past} \end{align}\]where
\[\begin{align} \mathrm{u_n^-=A_{n-1}u_{n-1}, \quad P_n^- = A_{n-1} P_{n-1} A_{n-1}^\intercal + Q_{n-1}. }\notag \end{align}\](II) By Lemma A.2 and Eq.\eqref{xk_given_y_past}, we have
\[\begin{align} \mathrm{P(x_n, y_n|y_{1:n-1})}&\mathrm{=P(y_n|x_n) P(x_n|y_{1:n-1}),} \notag\\ &=\mathrm{N(y_n|H_n x_n, R_n) N(u_n^-, P_n^-)}\notag\\ &=\mathrm{N}\bigg(\begin{bmatrix}\mathrm{x_n}\\ \mathrm{y_n} \end{bmatrix}\bigg| \mathrm{u}'', \mathrm{P}''\bigg),\notag\\ \end{align}\]where
\[\begin{align} \mathrm{u}''=\begin{bmatrix} \mathrm{u}_n' \\ \mathrm{H_n^- u_n^-} \end{bmatrix}, \qquad \mathrm{P}''=\begin{bmatrix} \mathrm{P}_n^- & \mathrm{P}_n^- \mathrm{H_n^\intercal} \\ \mathrm{H_n P_n^-} & \mathrm{H_n P_n^- H_n^\intercal + R_n} \end{bmatrix}.\notag \end{align}\](III) By Lemma A.2, we have
\[\begin{align} \mathrm{P(x_n|y_{1:n})=N(x_n|u_n, P_n),}\notag \end{align}\]where
\[\begin{align} \mathrm{u}_n &= \mathrm{u_n^- + K_n [y_n - H_n u_n^-]} \notag \\ \mathrm{P_n} &= \mathrm{P_n^- - K_n S_n K_n^\intercal} \notag \\ \mathrm{S_n} &= \mathrm{H_n P_n^- H_n^\intercal + R_n} \notag \\ \mathrm{K_n} &= \mathrm{P_n^- H_n^\intercal S_n^{-1}}. \notag\\ \end{align}\]Appendix
Lemma A.1 The joint distribution of $\mathrm{x, y}$ and the marginal $\mathrm{y}$ follows
\[\begin{align} (\mathrm{x}; \mathrm{y})&\sim \mathrm{N}\bigg(\begin{bmatrix}\mathrm{m} \\ \mathrm{Hm+u}\end{bmatrix}, \begin{bmatrix}\mathrm{P} & \mathrm{PH^\intercal} \\ \mathrm{HP} & \mathrm{HPH^\intercal +R}\end{bmatrix}\bigg) \notag\\ \mathrm{y}&\sim \mathrm{N}(\mathrm{H}\mathrm{M}+\mathrm{u}, \mathrm{H}\mathrm{P}\mathrm{H}^\intercal + \mathrm{R}).\notag \end{align}\]given that
\[\begin{align} \mathrm{x} &\sim \mathrm{N}(\mathrm{m}, \mathrm{P}) \notag\\ \mathrm{y|x} &\sim \mathrm{N}(\mathrm{H}\mathrm{x}+\mathrm{u}, \mathrm{R}).\notag \end{align}\]Proof \(\mathrm{Var[y]}\) can be solved by Lemma A.3. For another, we have
\[\begin{align} \mathrm{Cov(x, y)}&=\mathrm{E[xy^\textcolor{blue}{\intercal}]-E[x]E[y]}\notag \\ &=\mathrm{E[xx^\intercal H^\intercal+x u]-m (Hm+u)}\notag\\ &=\mathrm{P H^\intercal}.\notag\\ \end{align}\]Lemma A.2 The conditional distribution of $\mathrm{x}$ given $\mathrm{y}$ follows that
\[\begin{align} \mathrm{x|y} &\sim \mathrm{N(a + CB^{-1}(y-b), A-CB^{-1}C^\intercal)}.\notag \end{align}\]given that
\[\begin{align} \mathrm{(x; y) \sim N\bigg(\begin{bmatrix}\mathrm{a} \\ \mathrm{b} \end{bmatrix}, \begin{bmatrix}\mathrm{A} & \mathrm{C}\\ \mathrm{C^\intercal} & \mathrm{B}\end{bmatrix}}\bigg)\notag \end{align}\]Proof Denote by $\mathrm{\bar x=x-a}$ and $\mathrm{\bar y=y-b}$. The key lies in constructing a vector $\mathrm{\bar z}=\mathrm{M \bar x+N\bar y}$ s.t. $\mathrm{Cov(\bar z, \bar y)=M Cov(\bar x,\bar y)+N Cov(\bar y,\bar y)=0}$. It suffices to fix $\mathrm{M=I \ \text{and}\ N=-C B^{-1}}$.
Now we have $\mathrm{\bar z=\bar x-C B^{-1} \bar y,\ \ \bar x=\bar z+C B^{-1} \bar y}$. Since $\mathrm{E(Z)=0}$, we have \(\begin{align} \mathrm{E[\bar x|\bar y]}&=\mathrm{E[\bar z+C B^{-1} \bar y|\bar y]} = \mathrm{E[\bar z]+C B^{-1} \bar y=C B^{-1} \bar y}, \quad \mathrm{E[x|y]=a+C B^{-1} (y-b)} \notag.\\ \end{align}\)
\[\begin{align} \mathrm{Var[x|y]}&=\mathrm{Var[\bar x|\bar y]=Var[\bar z+C B^{-1} \bar y | \bar y]=Var[\bar z]}\notag \\ \mathrm{Var[\bar z]}&=\mathrm{Var[\bar x-C B^{-1}\bar y]=A+CB^{-1}C^\intercal-2 CB^{-1} C^\intercal,}\notag \end{align}\]where the first equality holds because \(\textcolor{darkblue}{\mathrm{Var[\bar z \\|\bar z]}=0}\).
Lemma A.3 Law of Total Variance
\[\begin{align} \mathrm{Var[y]=E[Var[y|x]] + Var[E[y|x]]}\notag. \end{align}\]Proof By the law of total expectation \(\mathrm{E[y]=E[E[y\\|x]]}\) and \(\mathrm{E[y^2]=Var[y] + E[y]^2}\), we have
\[\begin{align} \mathrm{E[y^2]=E[Var[y|x] + E[y|x]^2]}\notag. \end{align}\]We further have
\[\begin{align} \mathrm{Var[y]=E[y^2|x] - E[y]^2}&\mathrm{=E[Var[y|x] + E[y|x]^2]-E[y]^2}\notag \\ &=\mathrm{E[Var[y|x] + E[y|x]^2]-E[E[y|x]]^2}\notag \\ &=\mathrm{E[Var[y|x]] + E[E[y|x]^2]-E[[y|x]]^2}\notag \\ &=\mathrm{E[Var[y|x]] + Var[E[y|x]]}.\notag \end{align}\]Ensemble Kalman Filter
Kalman filter is not very scalable to high dimensions. To tackle this issue, ensemble Kalman filter (EnKF) proposes to propagate samples through a deterministic transport instead of employing the expensive Kalman gain $\mathrm{K}_n$ in Eq.\eqref{kalman_gain}. As a derivative-free Monte Carlo filter, the ensemble of samples implicitly yields a form of dimension reduction and greatly accelerates the algorithm (Katzfuss et al., 2016).
Given samples \(\{\mathrm{\widehat x}_{n-1}^{(i)}\}_{i=1}^{N}\) simulated from \eqref{filter_dist}, particles at step $n$ can be updated via Eq.\eqref{linear_ss}:
\[\begin{align} \mathrm{\widehat x}_{n}^{(i)} = \mathrm{f}(\widehat x_{n-1}^{(i)})+ \mathrm{w}_{n-1}^{(i)}, \ \ \mathrm{w}_{n-1}^{(i)}\sim \mathrm{N}(0, \mathrm{Q}_{n-1}).\notag \end{align}\]where $\mathrm{f}$ can be linear function driven by $\mathrm{A}_{n-1}$ or some general nonlinear functions.
The Kalman gain $\mathrm{K}_n$ in Eq.\eqref{kalman_gain} can be approximated by $\mathrm{\widehat K}_n$, which follows that
\[\begin{align} \mathrm{\widehat S_n} &= \mathrm{H_n \widehat P_n^- H_n^\intercal + R_n}\notag\\ \mathrm{\widehat K_n} &= \mathrm{\widehat P_n^- H_n^\intercal \widehat S_n^{-1}}, \notag\\ \end{align}\]where $\mathrm{\widehat P}_n$ is the empirical covariance of \(\{\mathrm{\widehat x}_{n-1}^{(i)}\}_{i=1}^{N}\) instead of the true covariance $\mathrm{P}_n$.
Large Sample Asymptotics
Intuitively, we expect EnKF will converge to KF when $\mathrm{N} \rightarrow \infty$ by invoking the law of large numbers. However, this only holds given linear state transitions with well-posed priors (Gland et al., 2011).
-
For state space system with Gaussian priors, the empirical mean and covariance via EnKF converges to the exact KF in the classical order of $\frac{1}{\sqrt{\mathrm{N}}}$.
-
When $\mathrm{f}$ is some general nonlinear function and when the prior is not linearly initialized, EnKF doesn’t converge to KF as $\mathrm{N} \rightarrow \infty$.
- Särkkä, S. (2023). Bayesian Filtering and Smoothing. Cambridge University Press.
- Katzfuss, M., Stroud, J. R., & Wikle, C. K. (2016). Understanding the Ensemble Kalman Filter. The American Statistician, Vol. 70, No.4, 350–357.
- Gland, F. L., Monbet, V., & Tran, V. (2011). Large Sample Asymptotics for the Ensemble Kalman Filter. The Oxford Handbook of Nonlinear Filtering.