Replica Exchange and Variance Reduction
Running multiple MCMCs at different temperatures to explore the solution thoroughly.
Variance-reduced sampling algorithms (Dubey et al., 2016) (Xu et al., 2018) are not widely adopted in practice. Alternatively, we focus on the energy variance reduction to exploit exponential accelerations but no longer consider the gradient variance reduction.
To this end, we consider a standard sampling algorithm, the stochastic gradient Langevin dynamics (SGLD), which is a mini-batch numerical discretization of a stochastic differential equation (SDE) as follows:
\begin{equation} \mathrm{\beta_{k+1}=\beta_k - \eta \frac{N}{n}\nabla \sum_{i\in B} L(x_i|\beta_k) + \sqrt{2\eta\tau_1} \xi_k,}\notag \end{equation}
where $\mathrm{\beta\in\mathbb{R}^d}$, $\mathrm{L(x_i|\beta)}$ is the energy function based on the i-th data point and B denotes a data set of size $n$ simulated from the whole data of size $\mathrm{N}$. $\mathrm{\xi}$ is a d-dimensional Gaussian vector. It is known that a non-convex $\mathrm{U(\cdot)}$ often leads to an exponentially slow mixing rate.
To accelerate the simulations, replica exchange proposes to run multiple stochastic processes with different temperatures, where interactions between different SGLD chains are conducted in a manner that encourages large jumps (Yin & Zhu, 2010) (Chen et al., 2019) (Deng et al., 2020) (Deng et al., 2021).
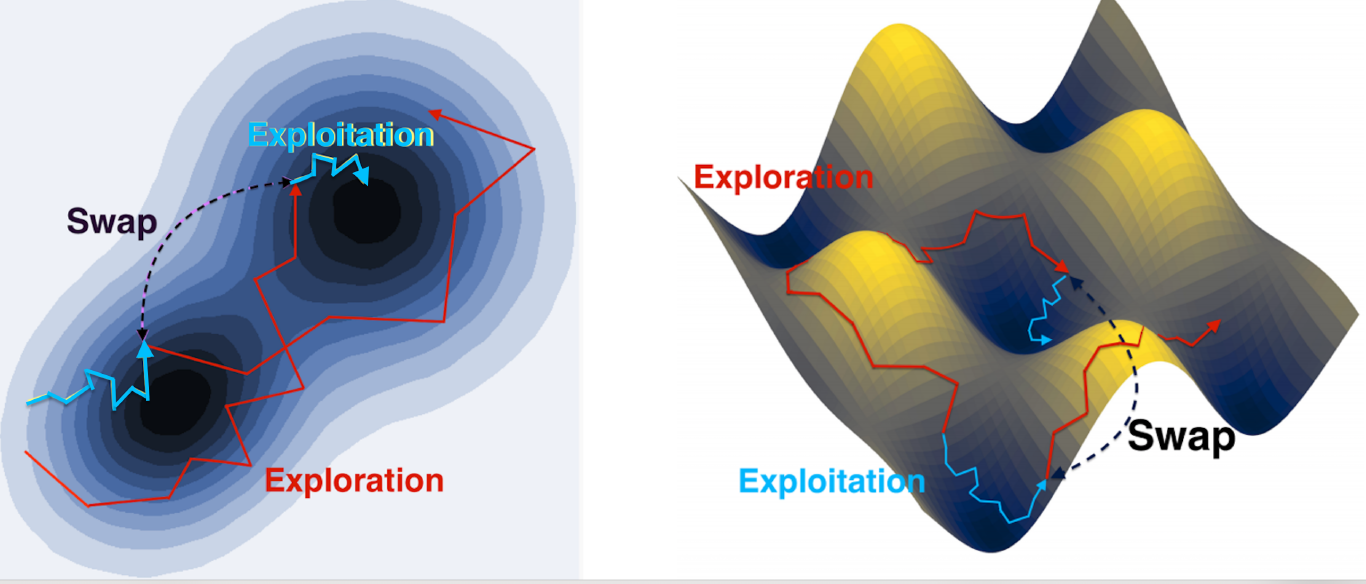
In particular, the parameters swap the positions with a probability $1\wedge S(\beta^{(1)}, \beta^{(2)})$
\begin{equation} \mathrm{S(\beta^{(1)}, \beta^{(2)})=e^{\left(\frac{1}{\tau_1}-\frac{1}{\tau_2}\right)\left(\frac{N}{n}\sum_{i\in B} L(x_i|\beta^{(1)})-\frac{N}{n}\sum_{i\in B} L(x_i|\beta^{(2)})-(\frac{1}{\tau_1}-\frac{1}{\tau_2})\sigma^2\right)},}\notag \end{equation}
where $\mathrm{\sigma^2}$ is the variance of the noisy estimators $\mathrm{\sum_{i\in B} L(x_i|\cdot)}$. Under Normality assumptions, the above rule leads to an unbiased swapping probability, which satisfy the detailed balance in a stochastic sense. However, the efficiency of the swaps are significantly reduced due to the requirement of corrections to avoid biases.
The desire to obtain more effective swaps drives us to design more efficient energy estimators. To reduce the variance of the noisy energy estimator $\mathrm{L(B|\beta^{(h)})=\frac{N}{n}\sum_{i\in B}L(x_i|\beta^{(h)})}$ for $\mathrm{h\in{1,2}}$, we consider an unbiased estimator $\mathrm{L(B|\widehat\beta^{(h)})}$ for $\mathrm{\sum_{i=1}^N L(x_i|\widehat\beta^{(h)})}$ and a constant $c$, we see that a new estimator $\mathrm{\widetilde L(B| \beta^{(h)})}$, which follows \begin{equation} \mathrm{\widetilde L(B|\beta^{(h)})= L(B|\beta^{(h)}) +c\left( L(B|\widehat\beta^{(h)}) -\sum_{i=1}^N L (x_i| \widehat \beta^{(h)})\right),}\notag \end{equation} is still the unbiased estimator for $\mathrm{\sum_{i=1}^N L(x_i| \beta^{(h)})}$. Moreover, energy variance reduction potentially increases the swapping efficiency exponentially given a larger batch size $n$, a small learning rate $\mathrm{\eta}$, and a more frequent update of control variate $\mathrm{\widehat \beta}$, i.e. a small $m$
\begin{equation} \mathrm{Var\left(\widetilde L(B|\beta^{(h)})\right)\leq O\left(\frac{m^2 \eta}{n}\right).}\notag \end{equation}
The following shows a demo that explains how variance-reduced reSGLD works.


- Dubey, A., Reddi, S. J., Póczos, B., Smola, A. J., Xing, E. P., & Williamson, S. A. (2016). Variance Reduction in Stochastic Gradient Langevin Dynamics. NeurIPS.
- Xu, P., Chen, J., Zou, D., & Gu, Q. (2018). Global Convergence of Langevin Dynamics Based Algorithms for Nonconvex Optimization. NeurIPS.
- Yin, G., & Zhu, C. (2010). Hybrid Switching Diffusions: Properties and Applications. Springer.
- Chen, Y., Chen, J., Dong, J., Peng, J., & Wang, Z. (2019). Accelerating Nonconvex Learning via Replica Exchange Langevin Diffusion. ICLR.
- Deng, W., Feng, Q., Gao, L., Liang, F., & Lin, G. (2020). Non-Convex Learning via Replica Exchange Stochastic Gradient MCMC. ICML.
- Deng, W., Feng, Q., Karagiannis, G., Lin, G., & Liang, F. (2021). Accelerating Convergence of Replica Exchange Stochastic Gradient MCMC via Variance Reduction. ICLR.